Capítulo 2: Treinamento de Foundation Models
Até agora exploramos a arquitetura dos Transformers, os componentes mecânicos que permitem processar linguagem. Mas arquitetura sozinha não cria inteligência. Um Transformer não-treinado, com pesos inicializados aleatoriamente, não possui capacidade de compreender ou gerar linguagem coerente.
A transformação de uma arquitetura vazia em um modelo capaz acontece através do aprendizado. Esta seção explora como LLMs adquirem conhecimento, desenvolvem capacidades linguísticas e, surpreendentemente, demonstram comportamentos que parecem ir além do que foi explicitamente ensinado.
O Paradigma de Pré-Treinamento
Imagine ensinar alguém a ser um médico. Você não começa ensinando cirurgias específicas. Primeiro, a pessoa passa por educação básica (fundamental e médio), depois graduação em medicina (conhecimento geral amplo), e só então se especializa em uma área específica. Os LLMs seguem um caminho similar através de um processo de duas fases: pré-treinamento e fine-tuning.
O pré-treinamento é onde a “mágica” acontece. É aqui que o modelo desenvolve sua compreensão fundamental de linguagem, absorve conhecimento sobre o mundo e, surpreendentemente, desenvolve capacidades rudimentares de raciocínio, tudo isso sem supervisão humana direta.
Pense no pré-treinamento como expor uma criança a milhões de livros, artigos, conversas e códigos. A criança não recebe instruções explícitas sobre gramática ou fatos, mas através da exposição massiva, começa a reconhecer padrões, entender estruturas linguísticas e absorver conhecimento implícito.
Durante o pré-treinamento, o modelo é exposto a um corpus gigantesco de texto não-anotado. A escala dos dados varia de centenas de gigabytes a terabytes de texto, abrangendo uma diversidade significativa de fontes: web pages, livros, código-fonte, artigos científicos e fóruns de discussão. Em termos quantitativos, isso representa trilhões de palavras (tokens), equivalente a milhares de anos de leitura humana contínua.
A tarefa de aprendizado é auto-supervisionada, ou seja, os dados criam seus próprios “rótulos” automaticamente, sem necessidade de anotação humana. Não há humanos rotulando “esta frase é sobre medicina” ou “este código está correto”. O modelo simplesmente observa padrões em dados brutos e aprende a modelar a distribuição estatística da linguagem natural.
Self-Supervised Learning: Aprendendo Sem Labels
O truque fundamental do pré-treinamento é usar self-supervision: criar tarefas de aprendizado automaticamente a partir de texto não-anotado. Para modelos decoder-only, a tarefa é predição do próximo token:
P(x_t | x_1, x_2, ..., x_{t-1})Dado um corpus de texto, simplesmente “escondemos” o próximo token e treinamos o modelo para prevê-lo. Não requer anotação humana, cada posição na sequência se torna automaticamente um exemplo de treinamento.
Esta tarefa aparentemente simples força o modelo a aprender representações extremamente ricas. Para prever o próximo token com precisão, o modelo precisa dominar múltiplas dimensões da linguagem. Primeiro, deve entender sintaxe, ou seja, a estrutura gramatical necessária para gerar continuações sintaticamente corretas. Segundo, precisa compreender semântica, capturando o significado para produzir continuações coerentes. Terceiro, deve adquirir conhecimento factual, memorizando informações sobre o mundo presentes nos dados de treinamento. Por fim, necessita desenvolver capacidades de raciocínio, realizando inferências lógicas para gerar continuações consistentes com o contexto.
Esta é uma das descobertas mais notáveis da era dos LLMs: uma tarefa de treinamento simples (next token prediction) em dados massivos resulta em capacidades emergentes complexas.
A Loss Function: Medindo o Aprendizado
Agora que entendemos o que o modelo aprende (prever o próximo token), precisamos entender como medimos se ele está aprendendo bem. Durante o treinamento, precisamos de uma forma matemática de dizer “essa previsão foi boa” ou “essa previsão foi ruim”. É aí que entra a loss function (função de perda).
Intuição: Quantificando a Qualidade das Previsões
Considere o problema de prever a próxima palavra em uma sequência. Dado o contexto, o modelo atribui probabilidades a cada candidato possível:
Contexto: "O gato está dormindo no..."
Distribuição de probabilidades:
- "sofá": 70%
- "chão": 20%
- "teto": 10%Se a palavra real for “sofá”, a previsão foi bem-sucedida. Se for “teto”, a previsão foi deficiente. A loss function quantifica matematicamente esse grau de acerto: quão surpreendente foi a resposta correta dada a distribuição de probabilidades predita.
Cross-Entropy: A Matemática da Surpresa
A função de loss usada é cross-entropy entre a distribuição prevista pelo modelo e a distribuição alvo (que é simplesmente: 100% para o token correto, 0% para todos os outros):
L = -Σ_t log P(x_t | x_<t)Isso pode parecer complicado, mas a interpretação não é tão difícil: cross-entropy mede quão surpreso o modelo está com o token correto. Se o modelo atribuiu alta probabilidade ao token correto, a loss é baixa (bom!). Se atribuiu baixa probabilidade, a loss é alta (ruim!). Não ligue para a fórmula exata, o conceito é o seguinte:
- Modelo confiante e correto: Atribuiu 90% de probabilidade ao token que realmente veio → Loss baixa (bom!)
- Modelo incerto ou errado: Atribuiu 5% de probabilidade ao token que realmente veio → Loss alta (ruim!)
Quanto menor a loss, melhor o modelo está prevendo. Durante o treinamento, o objetivo é minimizar essa loss ajustando os pesos do modelo através de backpropagation.
Perplexidade: Traduzindo Loss para Algo Mais Intuitivo
Embora loss seja útil matematicamente, é difícil interpretá-la diretamente. “Loss de 2.3” é bom ou ruim? É aí que entra a perplexidade, uma métrica mais intuitiva comumente reportada em papers:
PPL = exp(L)
onde L = -1/N Σ log P(x_t | x_<t)De novo, não se apegue à fórmula. A perplexidade pode ser entendida como a “média geométrica do número de escolhas que o modelo está considerando”.
Vamos aprofundar isso.
O que perplexidade significa?
Perplexidade pode ser interpretada como “o número efetivo de escolhas que o modelo está considerando a cada passo”. É como medir quão “confuso” o modelo está.
Exemplos práticos:
- Perplexidade = 2: O modelo está, em média, confuso entre 2 opções
- É como escolher entre “sim” ou “não” — bem confiante!
- Perplexidade = 10: O modelo está confuso entre ~10 opções
- Como escolher entre os 10 dígitos (0-9) — ainda razoável
- Perplexidade = 50.000: O modelo está confuso entre 50 mil opções
- Praticamente um chute aleatório no vocabulário inteiro!
Benchmarks de referência:
- Modelos state-of-the-art: Perplexidade de 3-5 em benchmarks como Penn Treebank
- O modelo está basicamente escolhendo entre 3-5 palavras plausíveis a cada passo
- Modelos de bigram (só olham a palavra anterior): Perplexidade de ~100
- Muito mais confuso, precisa considerar 100 opções
- Modelo aleatório: Perplexidade igual ao tamanho do vocabulário (~50.000)
- Completamente perdido, cada palavra é igualmente provável
Perplexidade nos dá uma forma intuitiva de avaliar e comparar modelos. Se você está treinando um modelo e vê a perplexidade cair de 100 para 10 e depois para 5, você sabe que o modelo está ficando progressivamente mais confiante e preciso nas suas previsões. É um indicador direto de que o modelo está realmente aprendendo a modelar a linguagem.
Limitações Importantes da Perplexidade
Embora perplexidade seja uma métrica útil, precisamos entender suas limitações para não tirar conclusões errôneas sobre a qualidade do modelo. Vamos explorar algumas das principais limitações.
1. Não Captura Qualidade Semântica
Perplexidade mede apenas previsibilidade estatística, não o significado ou a coerência:
- Um modelo pode ter perplexidade baixa gerando texto gramaticalmente correto mas semanticamente absurdo
- Exemplo: “O elefante verde comeu uma nuvem de metal” pode ter baixa perplexidade se as palavras forem comuns
- Correlação fraca com qualidade percebida por humanos em tarefas de geração
2. Vulnerável a Overfitting
Modelos podem “memorizar” padrões do conjunto de teste:
- Perplexidade pode melhorar artificialmente sem ganho real de capacidade de generalização
- Importante usar conjunto de validação separado e monitorar overfitting
- Modelos com perplexidade muito baixa podem estar apenas memorizando, não aprendendo padrões gerais
3. Não Comparável Entre Vocabulários Diferentes
Perplexidade depende fundamentalmente do tamanho do vocabulário:
- Modelo com vocab 50K terá perplexidade diferente de modelo com vocab 128K no mesmo dataset
- Tokenização diferente (BPE vs WordPiece vs caracteres) produz perplexidades incomparáveis
- Nunca compare perplexidade diretamente entre modelos com tokenizers diferentes
4. Correlação Imperfeita com Downstream Performance
Menor perplexidade ≠ melhor performance em tarefas práticas:
- Modelo A com perplexity 10 pode superar Modelo B com perplexity 8 em question answering
- Tasks específicas requerem capacidades além de modelagem de linguagem pura
- Importante avaliar em benchmarks downstream (GLUE, SuperGLUE, etc.) além de perplexity
5. Sensível ao Domínio dos Dados
Perplexidade é altamente dependente do domínio de avaliação:
- Modelo treinado em código terá baixa perplexity em código, alta em poesia
- Perplexity em Wikipedia ≠ perplexity em Twitter ≠ perplexity em documentos legais
- Sempre reporte o dataset de avaliação junto com a métrica
Recomendações Práticas:
- Use perplexidade como proxy inicial durante treinamento, mas não como métrica final
- Complemente com avaliações humanas e benchmarks downstream (Zheng et al. 2023)
- Compare apenas modelos com mesmo vocabulário e tokenização
- Monitore múltiplas métricas (perplexity, accuracy, F1, human eval) simultaneamente
Dados de Pré-Treinamento: A Matéria-Prima da Inteligência
Agora chegamos a uma verdade fundamental sobre LLMs: você é o que você come. Mais precisamente, o modelo sabe apenas o que viu. Não importa quão sofisticada seja a arquitetura Transformer ou quão bem otimizado seja o processo de treinamento, se os dados de entrada forem ruins, o modelo resultante será ruim.
Esta seção explora um dos aspectos mais subestimados, porém críticos, do desenvolvimento de LLMs: a curadoria de dados de treinamento. É aqui que decisões aparentemente simples, “quanto código incluir?” ou “devemos filtrar conteúdo controverso?”, têm consequências profundas e duradouras nas capacidades do modelo.
O ditado “garbage in, garbage out” nunca foi tão verdadeiro. A qualidade, diversidade e escala dos dados de pré-treinamento determinam fundamentalmente as capacidades do modelo final.
Isso já era perceptível antes dos LLMs, quando modelos de reconhecimento de fala ou visão computacional dependiam fortemente dos datasets usados. Com LLMs, essa dependência é ainda mais crítica devido à natureza estatística do aprendizado de linguagem.
Diferente de sistemas programados tradicionalmente, onde você especifica explicitamente o comportamento desejado, LLMs aprendem por imitação estatística. Eles absorvem padrões, conhecimento factual, estilo de escrita, vieses e até raciocínio dos dados que observam. Se o modelo nunca foi exposto a discussões médicas nos dados de treinamento, não desenvolverá conhecimento adequado sobre medicina e poderá gerar respostas factualmente incorretas sobre tópicos especializados, não importa quão grande seja o dataset.
Considere estas implicações práticas:
- Um modelo treinado principalmente em código Python será excelente em Python, mas medíocre em outras linguagens
- Um modelo treinado só em textos formais acadêmicos terá dificuldade com conversas casuais
- Um modelo treinado em dados até 2021 não “saberá” eventos posteriores a essa data
- Um modelo treinado em dados racistas reproduzirá esses vieses em suas saídas
Para engenheiros construindo sistemas de produção, isso significa que escolher o modelo certo requer entender seus dados de treinamento. Você está construindo um agente para análise jurídica? Vale investigar se o modelo foi treinado em documentos legais e como isso implica na vida do usuário final. Um agente para código? Verifique a proporção de código nos dados de treinamento. E assim por diante.
Composição de Datasets: A Receita do Conhecimento
Modelos modernos não são treinados em um único tipo de dados. Em vez disso, usam uma mixture cuidadosamente balanceada de múltiplas fontes, cada uma contribuindo diferentes tipos de conhecimento e capacidades (Gao et al. 2020; Dodge et al. 2021).
Os números de tokens na tabela são estimativas aproximadas baseadas em informações divulgadas em papers como The Pile (Gao et al. 2020), GPT-3 (Brown et al. 2020), e LLaMA (Touvron et al. 2023; Dubey et al. 2024). Datasets diferentes e versões de modelos usam proporções variadas, mas estes valores representam ordens de magnitude típicas em modelos state-of-the-art.
| Fonte | Escala (estimada) | O que contribui | Trade-offs |
|---|---|---|---|
| Common Crawl | ~3T tokens | Diversidade linguística, conhecimento geral da web, linguagem natural variada | Muito ruído, spam, conteúdo de baixa qualidade |
| Livros | ~200B tokens | Narrativas longas, coerência textual, vocabulário rico, conhecimento cultural | Viés para ficção/não-ficção publicada, direitos autorais |
| Wikipedia | ~10B tokens | Conhecimento factual verificado, escrita enciclopédica, estrutura bem organizada | Formal demais, cobertura desigual de tópicos |
| Código | ~300B tokens | Sintaxe de programação, lógica estruturada, resolução de problemas | Específico para desenvolvimento, menos útil para prosa |
| Papers Acadêmicos | ~50B tokens | Conhecimento técnico profundo, raciocínio científico, terminologia especializada | Muito formal, barreiras de jargão técnico |
A Arte da Proporção
A mistura dessas fontes não é arbitrária, é uma das decisões mais importantes no desenvolvimento de um LLM descente. Considere os trade-offs:
Cenário 1: Muito Common Crawl (>80%)
- Modelo entende linguagem natural diversa e coloquial
- Boa cobertura de tópicos contemporâneos
- Aprende padrões de spam, SEO gaming, conteúdo clickbait
- Pode reproduzir desinformação e teorias conspiratórias
Cenário 2: Muito Código (>50%)
- Excelente em programação e tarefas estruturadas
- Forte raciocínio lógico e pattern matching
- Piora significativa em prosa natural fluente
- Respostas podem parecer “robóticas” ou muito estruturadas
Cenário 3: Muito Texto Formal (Wikipedia + Papers >60%)
- Conhecimento factual robusto
- Escrita clara e bem estruturada
- Dificuldade com linguagem casual, gírias, humor
- Pode soar pedante ou acadêmico demais
Mixture Real (LLaMA 3 como exemplo):
Modelos como LLaMA 3 foram treinados em ~15 trilhões de tokens (Dubey et al. 2024) com uma mixture aproximadamente assim:
- Common Crawl filtrado: ~45%
- Código: ~30-35%
- Wikipedia/Enciclopédico: ~10%
- Books: ~10%
- Papers Acadêmicos: ~5%
As proporções acima são estimativas aproximadas baseadas em análises da comunidade e inferências de papers relacionados, não informações oficiais divulgadas pela Meta. O paper do LLaMA 3 (Dubey et al. 2024) confirma o volume total de ~15T tokens mas não detalha a composição exata do dataset de treinamento. Diferentes versões e variantes do modelo podem usar mixtures distintas.
Esta proporção foi determinada através de extensos experimentos empíricos, treinando modelos menores com diferentes mixtures e avaliando performance em benchmarks diversos. Não há fórmula teórica que diga “a mixture perfeita é X% código, Y% web”, é um trabalho extenso baseado em tentativa, erro e muitos testes.
Evolução Temporal dos Dados
Outro aspecto crítico: dados têm data de validade. O conhecimento do mundo muda:
- Eventos recentes (guerras, eleições, descobertas científicas)
- Mudanças tecnológicas (frameworks populares, best practices)
- Evolução cultural (memes, gírias, tendências sociais)
Um modelo treinado em dados até 2021 literalmente não “sabe” nada sobre eventos posteriores. Quando você pergunta sobre algo de 2023, ele está adivinhando baseado em padrões, não em conhecimento real. É por isso que modelos são periodicamente re-treinados ou atualizados com dados mais recentes. E é por isso que em agentes de IA, integrar fontes de conhecimento dinâmicas (APIs, bases de dados atualizadas) é crucial para manter um bom desempenho.
Data Cleaning: Transformando Lixo em Ouro
Se você baixar Common Crawl raw — um snapshot da web pública — terá dezenas de terabytes de… lixo. Literalmente 90%+ é inutilizável para treinar um modelo de qualidade (Luccioni e Viviano 2021). Data cleaning é o processo meticuloso de transformar esse oceano de sujeira em algo valioso (Dodge et al. 2021; Raffel et al. 2020).
Por que raw Common Crawl é inutilizável?
Um exemplo concreto do que você encontra:
<!-- 85% do conteúdo de uma página típica -->
<nav>Home | About | Contact | Login</nav>
<footer>Copyright 2023 | Privacy Policy | Terms</footer>
<script>gtag('UA-12345678-9')</script>
<!-- Anúncios, tracking pixels, etc. -->
<!-- Apenas 15% é conteúdo real útil -->
<article>
O artigo começa aqui...
</article>Uma proporção significativa do conteúdo disponível na web constitui ruído: texto repetitivo, vazio, de baixa qualidade, anúncios, spam, etc. Modelos treinados nesses dados aprendem esses padrões ruins e acabam reproduzindo-os.
Além disso, você encontra:
1. Código Boilerplate (Navigation, Footers, Sidebars)
- Menus de navegação repetidos em milhões de páginas
- Footers idênticos: “Copyright”, “Privacy Policy”, “Terms”
- Sidebars com “Related Articles” genéricos
- Problema: Modelo aprende que texto “bom” sempre tem “Home | About | Contact”
2. Spam e Conteúdo de Baixa Qualidade
- Páginas geradas automaticamente para SEO (“Best [X] in [City]” × 1000 cidades)
- Conteúdo duplicado word-for-word em milhares de sites
- Spam de comentários: “Nice post! Check out my site [spam link]”
- Problema: Modelo aprende padrões de spam como linguagem “normal”
3. Conteúdo Adulto e Tóxico
- Pornografia explícita
- Discurso de ódio, racismo, sexismo
- Conteúdo violento ou perturbador
- Problema: Modelo pode reproduzir linguagem tóxica ou gerar conteúdo inapropriado
4. Duplicação Massiva
- Mesma notícia copiada em 500 sites de notícias
- Wikipedia espelhada em dezenas de domains
- Fóruns que scraped conteúdo uns dos outros
- Problema: Modelo “memoriza” conteúdo específico devido à sobre-exposição
5. PII (Personally Identifiable Information)
- Emails, números de telefone, endereços
- Números de cartão de crédito (sim, estão na web)
- Dados médicos vazados
- Problema: Questões éticas, legais e de privacidade graves
6. Problemas de Copyright
- Livros digitalizados ilegalmente
- Artigos de jornais pagos copiados
- Código proprietário vazado
- Problema: Riscos legais massivos para quem usa o modelo
O Pipeline de Limpeza: Transformando Lixo em Ouro
Um pipeline típico de produção tem múltiplos estágios: Language Filtering, Quality Filtering, Deduplicação, PII Removal, Toxicity Filtering, Copyright Filtering. Cada estágio remove uma fração significativa do conteúdo bruto.
Estágio 1: Language Filtering
- Remove documentos em idiomas não-desejados
- Usa detecção de idioma (fastText, langdetect)
- Mantém: inglês, português, espanhol, etc. (dependendo do objetivo)
- Remove ~30-40% do crawl (páginas em idiomas raros ou misturados)
Estágio 2: Quality Filtering
Aplicando heurísticas de qualidade textual:
def is_high_quality(text):
"""Verifica qualidade do texto usando múltiplas heurísticas."""
stopword_ratio = count_stopwords(text) / len(text.split())
if stopword_ratio < 0.2: # Muito técnico ou spam
return False
if calculate_entropy(text) < 3.0: # Muito repetitivo
return False
if count_uppercase(text) / len(text) > 0.3: # MUITO SPAM
return False
return TruePara a implementação completa com todas as funções auxiliares (calculate_entropy, count_stopwords, count_duplicates), veja o Exemplo 1: Métricas de Qualidade de Dados.
Remove ~20-30% adicional (conteúdo de baixíssima qualidade)
Estágio 3: Deduplicação
Técnica sofisticada usando MinHash ou SimHash para detectar near-duplicates:
- Duplicação Exata: Fácil (hash MD5), remove cópias idênticas
- Near-Duplicates: Difícil — detecta documentos “quase iguais”
Exemplo: “A capital da França é Paris” vs “Paris é a capital da França” são semanticamente idênticos mas literalmente diferentes.
MinHash e Locality-Sensitive Hashing (LSH)
MinHash cria “fingerprints” compactas que preservam similaridade de Jaccard entre conjuntos. O algoritmo funciona da seguinte maneira:
- Representa documento como conjunto de n-gramas (ex: shingles de 3 palavras)
- Gera múltiplas hash functions (ex: 128 funções diferentes)
- Para cada hash function, calcula o valor mínimo do hash para todos os n-gramas
- Concatena os mínimos → signature compacta (128 valores em vez de milhares de n-gramas)
A probabilidade de duas signatures terem o mesmo valor em uma posição é igual à similaridade de Jaccard dos documentos originais.
Locality-Sensitive Hashing (LSH) acelera a busca por duplicatas (Indyk e Motwani 1998):
- Divide a signature em bandas (ex: 128 valores → 32 bandas de 4 valores)
- Documentos com mesma banda → candidatos a duplicatas (verificação mais detalhada)
- Trade-off de parâmetros:
- Mais bandas/menos linhas → detecta duplicatas com menor similaridade (mais sensível, mais false positives)
- Menos bandas/mais linhas → detecta apenas duplicatas muito similares (menos sensível, menos false positives)
Implementação prática com datasketch: (Zhu 2024; Broder 1997)
from datasketch import MinHash, MinHashLSH
# Configurar LSH para detectar docs com similaridade >= 80%
lsh = MinHashLSH(threshold=0.8, num_perm=128)
def get_minhash(text, num_perm=128):
m = MinHash(num_perm=num_perm)
for word in text.lower().split():
m.update(word.encode('utf8'))
return m
# Indexar e buscar duplicatas
for doc_id, text in docs.items():
lsh.insert(doc_id, get_minhash(text))
duplicates = lsh.query(get_minhash("A França tem Paris como capital"))Para o exemplo completo com explicação detalhada do algoritmo MinHash e LSH, veja o Exemplo 2: Deduplicação com MinHash e LSH.
Performance: LSH permite buscar duplicatas em O(1) em média (tempo constante), em vez de O(n) comparando com todos os documentos. Isso é crucial quando processando bilhões de documentos.
Remove ~20-30% adicional do corpus (conteúdo duplicado ou near-duplicate)
Estágio 4: PII Removal
Usando regex patterns e NER (Named Entity Recognition):
import re
patterns = {
'email': r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b',
'phone': r'\b\d{3}[-.]?\d{3}[-.]?\d{4}\b',
'ssn': r'\b\d{3}-\d{2}-\d{4}\b',
'credit_card': r'\b\d{4}[- ]?\d{4}[- ]?\d{4}[- ]?\d{4}\b'
}
# Substituir por placeholders ou remover
text = re.sub(patterns['email'], '[EMAIL]', text)NER detecta nomes de pessoas, organizações, localizações e os redacta ou contextualiza apropriadamente.
Estágio 5: Toxicity Filtering
Usa modelos treinados para detectar conteúdo tóxico. Ferramentas comuns incluem a Perspective API do Google, que fornece scores de toxicidade entre 0 e 1, o Detoxify (modelo open-source especializado em hate speech), e filtros customizados baseados em listas de palavras ofensivas.
O Problema: Filtrar conteúdo tóxico é essencial para criar modelos seguros, mas filtros agressivos demais podem causar danos não intencionais. Aqui estão alguns exemplos de como isso pode acontecer:
1. Apagamento de Vozes Marginalizadas
Discussões sobre racismo, homofobia ou sexismo frequentemente contêm as palavras que descrevem esses problemas. Filtros baseados em keywords podem remover testemunhos de vítimas e discussões educacionais.
Exemplo: Um texto dizendo “Sofri racismo no trabalho quando me chamaram de…” pode ser filtrado pelo termo ofensivo, removendo justamente o relato que documenta discriminação.
2. Viés de Representação
Se termos relacionados a “LGBTQ+”, “transgênero” ou “orientação sexual” disparam filtros de conteúdo adulto (comum em sistemas mal calibrados), o modelo aprenderá menos sobre essas comunidades, perpetuando invisibilidade.
3. Remoção de Contexto Educacional
Textos médicos, históricos ou jornalísticos sobre tópicos sensíveis podem ser filtrados incorretamente: - Artigos sobre saúde sexual - Documentação histórica de genocídios - Reportagens investigativas sobre crimes
Abordagens Recomendadas:
A implementação responsável de filtros de toxicidade requer uma abordagem multifacetada. Primeiramente, é fundamental utilizar filtros contextuais baseados em modelos que compreendem o contexto (como a Perspective API com context awareness), em vez de sistemas simplistas baseados apenas em keywords. Essa abordagem reduz falsos positivos significativamente.
Em segundo lugar, recomenda-se manter allowlists educacionais contendo termos técnicos, médicos e acadêmicos que devem ser preservados mesmo quando aparecem em contextos sensíveis. Isso garante que conteúdo educacional legítimo não seja removido inadvertidamente.
A documentação transparente também é essencial: as organizações devem publicar estatísticas detalhadas de filtragem para permitir auditoria externa. Essas estatísticas devem responder a questões críticas como quantos textos foram removidos, quais categorias foram mais afetadas, e como a filtragem impacta a representação de grupos minoritários nos dados finais.
Por fim, é crucial realizar avaliação sistemática de viés, testando se os processos de filtragem afetam desproporcionalmente certos grupos demográficos. Isso inclui comparar taxas de remoção entre textos sobre diferentes comunidades e medir a representação antes e após a filtragem para identificar e corrigir disparidades.
Referência: Ver discussão em Dodge et al. (2021) sobre documentação ética de corpus.
Trade-off fundamental: filtrar agressivamente remove conteúdo tóxico mas também pode remover discussões legítimas sobre tópicos sensíveis. A calibração correta requer balanceamento cuidadoso e consciente entre segurança e representatividade.
Estágio 6: Copyright Filtering e Implicações Legais
A filtragem de conteúdo protegido por direitos autorais é um dos desafios mais complexos e controversos no treinamento de LLMs. Aqui a linha entre o tecnicamente possível e o eticamente/legalmente aceitável fica especialmente turva.
Técnicas de Detecção:
- N-gram matching: Detecta trechos de livros conhecidos comparando sequências de palavras
- Fingerprinting: Identifica artigos de jornais pagos via hashing
- License detection: Filtra código com licenças restritivas (GPL strict, proprietary)
- Metadata checking: Verifica robots.txt e meta tags de propriedade
O Dilema Legal e Ético
A questão central é: treinar um modelo em dados protegidos constitui “fair use” ou é violação de copyright? Esta pergunta ainda não tem resposta definitiva na maioria das jurisdições.
Argumentos pró “Fair Use”: 1. Transformative use: O modelo não reproduz o conteúdo original, mas aprende padrões estatísticos 2. Análogo a leitura humana: Humanos leem livros protegidos para aprender a escrever 3. Uso não-comercial direto: O treinamento em si não comercializa o conteúdo
Argumentos contra: 1. Memorização: Modelos podem reproduzir trechos literais de dados de treinamento 2. Competição: Modelos treinados competem com o material original 3. Escala: Diferença qualitativa entre um humano ler e processar milhões de obras
Casos Reais e Processos em Andamento
Até 2024, múltiplos processos judiciais estão em curso:
- Getty Images vs Stability AI (2023): Alegação de uso indevido de milhões de imagens protegidas para treinar modelos de geração de imagens
- Authors Guild vs OpenAI (2023): Autores alegando que GPT foi treinado em suas obras sem permissão
- The New York Times vs OpenAI/Microsoft (2023): Alegação de uso indevido de artigos protegidos
Estes casos estabelecerão precedentes importantes para a indústria.
LGPD, GDPR e Privacidade de Dados
Além de copyright, há questões de privacidade de dados pessoais:
GDPR (Europa) - Implicações para LLMs:
- Direito ao esquecimento: Como “remover” dados de um modelo já treinado?
- Consentimento: Dados pessoais requerem consentimento explícito para processamento
- Transparência: Usuários têm direito de saber se seus dados foram usados
LGPD (Brasil) - Considerações similares:
- Base legal: Treinar em dados pessoais sem consentimento viola LGPD Art. 7°
- Dados sensíveis: Informações sobre saúde, orientação sexual, etc. requerem proteções adicionais
- Responsabilização: Quem é responsável se o modelo vazar PII?
Consequências Práticas para Desenvolvedores:
- Auditorias de dados: Documentar origem e licenças de todos os dados de treinamento
- Filtros conservadores: Na dúvida, remover conteúdo questionável
- Modelos defensivos: Implementar mecanismos anti-memorização
- Transparência: Publicar cards de modelo documentando fontes de dados
Recomendações Éticas:
- Priorizar dados permissivos: Usar Common Crawl, Wikipedia, código open-source
- Respeitar opt-out: Honrar robots.txt e meta tags de exclusão
- Investir em dados sintéticos: Gerar dados via modelos já treinados (evita questões legais)
- Colaborar com criadores: Estabelecer parcerias com detentores de direitos
A realidade é que os limites legais ainda estão sendo definidos pelos tribunais. Enquanto isso, a responsabilidade ética recai sobre desenvolvedores e organizações em praticar a devida diligência e transparência.
Resultado Final
Após todos esses estágios, o resultado típico é:
- Entrada: 100TB de Common Crawl raw
- Saída: 5-10TB de texto limpo e de qualidade
- Taxa de rejeição: ~90-95%
Isso não é desperdício, é essencial. Os 5-10TB restantes são ordens de magnitude mais valiosos que os 100TB originais.
O Custo Oculto
Data cleaning é:
- Caro: Requer computação massiva para processar petabytes
- Demorado: Pode levar semanas ou MESES
- Trabalhoso: Requer expertise em NLP, sistemas distribuídos
- Iterativo: Múltiplas passagens, refinamento constante
Mas é absolutamente crítico. A diferença entre GPT-3/4/5 e um modelo medíocre não está apenas na arquitetura, está na qualidade dos dados de treinamento.
Data Cleaning em Produção: Ferramentas e Práticas
Para engenheiros implementando pipelines de data cleaning em escala, aqui estão as considerações práticas:
1. Ferramentas de Processamento Distribuído
Processar petabytes requer computação distribuída (Zaharia et al. 2016; Rocklin 2015; Moritz et al. 2018):
Apache Spark (Apache Software Foundation 2024)
- Framework mais popular para data cleaning em escala
- Suporta processamento de texto, deduplicação, filtering
- Pode processar 100TB+ em clusters distribuídos
- Exemplo: EleutherAI usou Spark para limpar The Pile
from pyspark.sql import SparkSession
from pyspark.sql.functions import length, col
spark = SparkSession.builder.appName("DataCleaning").getOrCreate()
# Carregar Common Crawl
df = spark.read.parquet("s3://commoncrawl/...")
# Aplicar filtros de qualidade
cleaned = df.filter(
(length(col("text")) > 100) & # Mínimo 100 caracteres
(col("language") == "en") & # Apenas inglês
(col("quality_score") > 0.7) # Score de qualidade
)
cleaned.write.parquet("s3://cleaned-data/")Dask / Ray (Dask Development Team 2024; Anyscale Inc. 2024)
- Alternativas Python-first ao Spark
- Melhor integração com ecosystem Python (scikit-learn, pandas)
- Ray especialmente bom para pipelines complexos com ML
2. Reprodutibilidade e Versioning
Data cleaning não é determinístico por padrão. Garantir reprodutibilidade é crucial:
Data Version Control (DVC) (Iterative.ai 2024; Petrov 2019)
# Versionar datasets como código
dvc add data/raw/commoncrawl.parquet
dvc push
# Pipeline reproduzível
dvc run -n clean_data \
-d data/raw/commoncrawl.parquet \
-o data/cleaned/output.parquet \
python scripts/clean_data.pyChecksum e Hashing
Uma prática essencial é aplicar hashing (MD5 ou SHA256) a cada estágio do pipeline de processamento. Isso permite detectar mudanças inesperadas nos dados e garantir que experimentos sejam reproduzíveis ao longo do tempo.
Data Lineage Tracking
O rastreamento da linhagem de dados é fundamental para auditabilidade e debugging. Isso envolve documentar a proveniência (de onde cada dado veio) e rastrear todas as transformações aplicadas em cada estágio do pipeline. Ferramentas como Apache Atlas, Marquez e OpenLineage facilitam essa tarefa em ambientes de produção.
3. Métricas de Qualidade Objetivas
Não confie em intuição. Defina métricas quantitativas:
import numpy as np
from collections import Counter
def compute_quality_metrics(dataset):
"""Métricas objetivas de qualidade do dataset"""
metrics = {
# Diversidade vocabular
"unique_tokens": len(set(dataset.split())),
"type_token_ratio": len(set(dataset.split())) / len(dataset.split()),
# Comprimento
"avg_doc_length": np.mean([len(doc.split()) for doc in dataset]),
"median_doc_length": np.median([len(doc.split()) for doc in dataset]),
# Duplicação
"duplicate_rate": count_near_duplicates(dataset) / len(dataset),
# Qualidade
"avg_quality_score": np.mean([quality_score(doc) for doc in dataset]),
# Cobertura de domínios
"domain_distribution": Counter([extract_domain(doc) for doc in dataset])
}
return metrics
# Monitorar ao longo do pipeline
raw_metrics = compute_quality_metrics(raw_data)
cleaned_metrics = compute_quality_metrics(cleaned_data)
# Validar mudanças esperadas
assert cleaned_metrics["duplicate_rate"] < raw_metrics["duplicate_rate"]
assert cleaned_metrics["avg_quality_score"] > raw_metrics["avg_quality_score"]As funções auxiliares count_near_duplicates, quality_score e extract_domain estão implementadas no Exemplo 1: Métricas de Qualidade de Dados.
4. Handling de Edge Cases
Casos especiais que pipelines simples não capturam:
Documentos Multilíngues
from langdetect import detect_langs
def handle_multilingual(text, threshold=0.8):
"""Detecta documentos code-switched ou multilíngues"""
langs = detect_langs(text)
primary_lang = langs[0]
if primary_lang.prob < threshold:
# Documento multilíngue ou ambíguo
return "REJECT" # ou processar especialmente
return primary_lang.langCódigo Mixed com Prosa
Documentos técnicos frequentemente misturam código-fonte e texto explicativo. A decisão de como processar esses documentos (separar, manter junto, ou processar diferentemente) depende dos objetivos do modelo. Uma estratégia comum é detectar blocos de código através de indentação ou syntax highlighting e marcá-los explicitamente para processamento diferenciado.
Tabelas e Listas
Elementos estruturados como HTML tables, markdown tables e bullet points apresentam um desafio particular: podem conter informação valiosa (dados estruturados) ou constituir ruído (navigation bars). A classificação apropriada requer heurísticas baseadas no tamanho da tabela, contexto em que aparece, e análise do conteúdo das células.
5. Monitoramento Contínuo
Data cleaning não é “one-and-done”. Monitore qualidade ao longo do tempo:
# Dashboard de métricas (Grafana, Datadog, etc.)
log_metric("dataset.size_gb", dataset_size_gb)
log_metric("dataset.duplicate_rate", duplicate_rate)
log_metric("dataset.avg_quality", avg_quality)
log_metric("dataset.processing_time_hours", processing_time)
# Alertas para anomalias
if duplicate_rate > 0.15: # Threshold esperado
send_alert("High duplicate rate detected!")
if avg_quality < 0.6:
send_alert("Quality degradation detected!")Trade-offs de Produção:
| Aspecto | Trade-off | Recomendação |
|---|---|---|
| Agressividade de Filtering | Mais filtros = menos dados mas maior qualidade | Comece conservador, aumente gradualmente |
| Velocidade vs Qualidade | Processar rápido vs aplicar filtros complexos | Itere: primeiro rápido e simples, refine depois |
| Custo de Computação | Clusters grandes = rápido mas caro | Use spot instances, processamento batch |
| Reprodutibilidade | Determinismo perfeito = mais overhead | Vale o custo para experimentos científicos |
Implicações para Construção de Agentes
Para você que está construindo agentes com LLMs, entender dados de treinamento é extremamente importante. Aqui estão algumas considerações práticas:
1. Escolha de Modelo
Pergunte: “Meu domínio estava bem representado nos dados de treinamento?”
Exemplos:
- Agente médico: Modelo treinado em papers médicos?
- Agente legal: Modelo viu contratos, jurisprudência?
- Agente código: Que linguagens estavam no treinamento?
Se o modelo não foi treinado no seu domínio, as respostas podem ser superficiais ou erradas e todo o nosso esforço de construção de agentes eficientes pode ser em vão.
2. Limitações de Conhecimento
O modelo “sabe” apenas o que viu:
- Data cutoff: Nada após a data de treinamento
- Cobertura geográfica: Viés para conteúdo em inglês/ocidental
- Tópicos de nicho: Conhecimento superficial se não estava nos dados
3. “Augmentação” via RAG
Para domínios específicos, Retrieval-Augmented Generation (RAG) complementa o conhecimento do modelo:
- Busca documentos relevantes do seu domínio
- Injeta no contexto antes da geração
- Compensa lacunas nos dados de treinamento
Porém, isso gera um trade-off entre latência, custo e complexidade. Se o modelo já é ruim, RAG não salva. Vamos explorar RAG em profundidade no Capítulo 5.
4. Fine-Tuning Domínio-Específico
Se o modelo base não foi treinado no seu domínio:
- Continue pré-treinamento com seus dados
- Fine-tune em exemplos do seu domínio
- Mas cuidado com catastrophic forgetting!
A mensagem fundamental: dados são o coração do modelo. Arquitetura sofisticada com dados ruins produz um modelo ruim. Arquitetura simples com dados excelentes produz um modelo excelente.
Tokenização: A Camada Crítica Entre Texto e Modelo
Antes de qualquer processamento neural acontecer, o texto precisa ser convertido em tokens, as unidades atômicas que o modelo realmente processa. Tokenização não é apenas “dividir texto em pedaços”, é uma compressão lossy que determina o que o modelo pode aprender e como ele generaliza. Uma má escolha de tokenização pode degradar performance em 10-20% mesmo com arquitetura e treinamento perfeitos, e diferentemente de hiperparâmetros, não pode ser ajustada depois do treinamento sem re-treinar o modelo do zero.
O Problema Fundamental: Granularidade vs. Vocabulário
Todo esquema de tokenização enfrenta um trade-off fundamental entre três fatores conflitantes: tamanho do vocabulário, comprimento da sequência e capacidade de generalização. Vamos dissecar cada um:
1. Tamanho do Vocabulário
- Vocabulário maior = mais parâmetros na embedding layer e na camada de saída
Exemplo com vocabulário tradicional (50K tokens, dimensão 4096):
- Embedding layer: 50K × 4096 = 200M parâmetros
- Output layer (logits): 4096 × 50K = 200M parâmetros
- Total: 400M parâmetros só para vocabulário (~0.5% de um modelo 70B)
Exemplo com vocabulário moderno (128K tokens, dimensão 8192):
Modelos modernos como LLaMA 3 70B usam vocabulários maiores e dimensões maiores: - Embedding layer: 128K × 8192 = 1.05B parâmetros - Output layer (logits): 8192 × 128K = 1.05B parâmetros - Total: 2.1B parâmetros para vocabulário (~3% de um modelo 70B)
Trade-off: Vocabulários maiores capturam mais nuances linguísticas e melhoram eficiência de tokenização (menos tokens por texto), mas aumentam significativamente o custo de memória e computação.
2. Comprimento de Sequência
- Tokens mais granulares (ex: caracteres) = sequências mais longas
- Atenção é O(n²): Dobrar o comprimento = 4× mais computação
- Context window limitado: Mais tokens = menos contexto real
3. Capacidade de Generalização
- Vocabulário pequeno força o modelo a compor significados
- Vocabulário grande permite memorização direta de padrões
Não há solução perfeita, apenas trade-offs conscientes com os quais engenheiros de machine learning devem lidar.
Vamos explorar os extremos e a solução intermediária mais popular.
Tokenização por Caracteres: O Extremo Composicional
Tokenização por caracteres usa cada caractere como um token (ex: UTF-8 bytes = 256 tokens possíveis).
Vantagens:
- Vocabulário minúsculo: 256 tokens para UTF-8
- Zero out-of-vocabulary (OOV): Qualquer string Unicode é representável
- Máxima generalização: Modelo precisa aprender composição desde o nível mais básico
Desvantagens Práticas:
Considere a frase “The transformer architecture revolutionized NLP”:
Tokenização por palavras: 5 tokens
Tokenização por caracteres: 51 tokens (incluindo espaços)Isso significa
- 10× mais tokens para representar o mesmo conteúdo
- 100× mais computação na atenção (O(n²))
- Context window de 4096 tokens de caracteres = apenas ~800 palavras de contexto real
Performance Real:
Modelos baseados em caracteres historicamente apresentam performance inferior a modelos baseados em subwords. Por exemplo, o paper de Kawakami et al. (2017) (Kawakami et al. 2017) reporta que modelos character-level atingem perplexidades significativamente maiores (piores) em benchmarks padrão. Modelos modernos character-level como ByT5 (Xue et al. 2022) melhoraram essa lacuna, mas ainda requerem arquiteturas mais profundas e treinamento mais custoso para alcançar performance comparável a modelos subword-based. O problema fundamental é que forçar o modelo a “redescobrir” palavras a partir de caracteres desperdiça sua capacidade representacional em padrões de baixo nível.
Quando Faz Sentido:
Tokenização character-level é adequada para cenários específicos. Tasks onde a morfologia é crítica (como correção ortográfica e transliteração) se beneficiam dessa granularidade. Idiomas com morfologia rica, como Turco e Finlandês, também podem se beneficiar da abordagem. Finalmente, aplicações que requerem robustez absoluta a typos e palavras fora do vocabulário podem justificar o overhead computacional adicional.
Tokenização por Palavras: O Extremo Lexical
Tokenização por palavras trata cada palavra como um token atômico.
Aparentemente Ideal:
Parece natural: palavras são unidades semânticas, certo? Em inglês, talvez. Mas considere:
Problema 1: Explosão de Vocabulário
Vocabulário real de inglês: ~170K palavras ativas, ~470K no total incluindo jargões técnicos.
A complexidade aumenta consideravelmente quando consideramos inflexões (run, runs, running, ran exigem 4 tokens diferentes), variantes ortográficas regionais (color/colour, organize/organise), compostos com múltiplas grafias (“machine learning”, “machine-learning”, “machinelearning”), milhões de nomes próprios (pessoas, lugares, empresas), a questão de como tratar números (cada número é uma “palavra” diferente?), e typos comuns que aparecem frequentemente em dados reais (“teh”, “recieve”, etc.).
O resultado é um vocabulário realista de 500K-1M+ tokens para cobertura razoável.
Custo Computacional:
Para vocabulário de 500K e modelo com d=4096 (onde d é a dimensão do modelo, o tamanho do vetor que representa cada token internamente, também chamada de hidden size ou d_model):
- Embedding: 500K × 4096 = 2B parâmetros
- Output layer: 4096 × 500K = 2B parâmetros
- Total: 4B parâmetros (>5% de um modelo 70B) gastos apenas no vocabulário
Isso é insustentável. Pior ainda: a maioria desses tokens será vista raramente, resultando em embeddings mal-treinadas.
Problema 2: Out-of-Vocabulary (OOV)
Qualquer palavra não vista no treinamento vira <unk> (unknown token), e o modelo perde completamente a informação:
"The cytokine storm caused by SARS-CoV-2 infection"
→ ["The", "<unk>", "storm", "caused", "by", "<unk>", "infection"]Por que isso é crítico:
- Perda de Informação Semântica: O modelo não consegue decompor “cytokine” em componentes significativos como “cyto-” (célula) + “-kine” (movimento) para inferir que se trata de uma molécula de sinalização celular.
- Todas as palavras desconhecidas colapsam no mesmo token: “cytokine”, “melatonin”, “serotonin” e qualquer termo técnico se tornam indistinguíveis, todos viram o mesmo
<unk>. O modelo não pode aprender nem generalizar. - Problema em Domínios Especializados: Em textos médicos, legais ou científicos, 15-30% dos tokens podem ser OOV, tornando o modelo praticamente inútil sem fine-tuning massivo.
- Números e Código: Cada número ou identificador único vira
<unk>, impossibilitando raciocínio aritmético ou compreensão de código.
Problema 3: Ineficiência Multilíngue
Idiomas aglutinantes como Alemão, Turco, Finlandês e Húngaro têm palavras compostas arbitrariamente longas formadas pela concatenação produtiva de morfemas:
Alemão: "Donaudampfschifffahrtselektrizitätenhauptbetriebswerkbauunterbeamtengesellschaft"
(Associação de funcionários subordinados do chefe de administração dos serviços elétricos de vapor de Danúbio)
Turco: "muvaffakiyetsizleştiricileştiriveremeyebileceklerimizdenmişsinizcesine"
(como se você fosse daqueles que não poderíamos facilmente transformar em um fracasso)Problemas Técnicos Concretos:
- Explosão Combinatória do Vocabulário: Em Alemão, “Software” pode combinar com centenas de substantivos: “Softwareentwicklung” (desenvolvimento), “Softwarearchitektur” (arquitetura), “Softwarequalität” (qualidade). Cada combinação seria um token único (Ács 2019).
- Distribuição de Frequência Extremamente Long-Tail: A palavra composta “Softwareentwicklungsingenieur” (engenheiro de desenvolvimento de software) pode aparecer 100 vezes no corpus. Mas suas variações “Softwareentwicklungsingenieurbüro” (escritório de engenheiros…), “Softwareentwicklungsingenieurteam” (equipe de engenheiros…) aparecem 2-3 vezes. Resultado: milhares de tokens com frequência < 10, embeddings subtreinadas.
- Ineficiência de Representação: Para cobrir razoavelmente Alemão técnico, precisaríamos de ~2M+ tokens no vocabulário apenas para esse idioma. Em modelos multilíngues, isso significa que ~80-90% dos slots de vocabulário são desperdiçados em variações que aparecem < 5 vezes no treinamento (Chung et al. 2020).
- Impacto em Modelos Multilíngues: GPT-3 com vocabulário de 50K tokens aloca ~40K para Inglês, sobrando apenas ~10K para todos os outros idiomas (Brown et al. 2020). Resultado: textos em Tailandês, Árabe ou Finlandês usam 3-5× mais tokens que Inglês para o mesmo conteúdo, custando mais e sendo truncados mais facilmente (Rust et al. 2021).
Byte Pair Encoding (BPE): O Compromisso Ótimo
Byte Pair Encoding (BPE) (Sennrich, Haddow, e Birch 2016) resolve simultaneamente todos os problemas anteriores através de um princípio elegante: construir vocabulário bottom-up baseado em frequência estatística dos dados. Originalmente um algoritmo de compressão de dados dos anos 1994, BPE foi adaptado para NLP por Sennrich et al. em 2016 especificamente para tradução neural, e desde então tornou-se o padrão de facto para tokenização em LLMs. Hoje é usado por GPT, LLaMA, Claude, Mistral e praticamente todos os LLMs modernos.
O que BPE garante:
- Zero OOV: Sempre pode decompor qualquer palavra em subwords ou, no pior caso, caracteres/bytes individuais
- Vocabulário fixo e controlado: Tipicamente 32K-100K tokens — balanceando eficiência e custo computacional
- Adaptativo aos dados: Tokens comuns (como “the”, “ing”, “tion”) emergem naturalmente da frequência no corpus
- Multilíngue eficiente: Morfemas compartilhados entre idiomas são reutilizados (ex: “inter-”, “anti-”, “-tion”)
- Determinístico e reversível: Mesma entrada sempre produz mesma tokenização
Trade-off fundamental: BPE sacrifica tokenização semanticamente perfeita (que exigiria compreensão linguística profunda) por tokenização estatisticamente ótima baseada apenas em co-ocorrências, o que funciona surpreendentemente bem na prática.
Algoritmo Detalhado:
Passo 1: Inicialização
Comece com vocabulário de caracteres individuais (ou bytes UTF-8):
vocab = ['a', 'b', 'c', ..., 'z', ' ', '.', '!', ...] # ~256 symbols
corpus = ["low", "lower", "newest", "widest"]Represente corpus como sequências de caracteres:
"low" -> ['l', 'o', 'w']
"lower" -> ['l', 'o', 'w', 'e', 'r']
"newest" -> ['n', 'e', 'w', 'e', 's', 't']
"widest" -> ['w', 'i', 'd', 'e', 's', 't']Passo 2: Contar Pares Adjacentes
('l', 'o'): 2 ocorrências
('o', 'w'): 2 ocorrências ← mais frequente
('w', 'e'): 2 ocorrências ← também frequente
('e', 's'): 2 ocorrências
('s', 't'): 2 ocorrências
...Passo 3: Merge do Par Mais Frequente
Merge (‘o’, ‘w’) → ‘ow’, adicione ao vocabulário:
vocab.append('ow')Atualize corpus:
"low" -> ['l', 'ow']
"lower" -> ['l', 'ow', 'e', 'r']
"newest" -> ['n', 'e', 'w', 'e', 's', 't'] # não afetado
"widest" -> ['w', 'i', 'd', 'e', 's', 't'] # não afetadoPasso 4: Repetir até Vocabulário Desejado
Continue mergindo pares mais frequentes:
Iteração 2: ('e', 's') → 'es'
Iteração 3: ('es', 't') → 'est'
Iteração 4: ('l', 'ow') → 'low'
Iteração 5: ('n', 'e') → 'ne'
...Resultado final após várias iterações:
"low" -> ['low'] # palavra completa
"lower" -> ['low', 'er'] # subwords semânticos
"newest" -> ['new', 'est'] # subwords semânticos
"widest" -> ['wid', 'est'] # subwords semânticosPropriedades Emergentes Poderosas:
- Palavras Comuns = Tokens Únicos
Palavras frequentes são rapidamente merged em tokens únicos:
"the" -> ["the"] # palavra completa, 1 token
"and" -> ["and"] # palavra completa, 1 tokenIsso mantém eficiência para o texto comum.
- Palavras Raras = Composição de Subwords
Palavras raras são naturalmente decompostas:
"unhappiness" -> ["un", "happi", "ness"]
# Cada subword tem significado: un- (negação), happi (feliz), -ness (estado)O modelo pode inferir significado através da composição, mesmo nunca tendo visto “unhappiness” inteiro.
- Zero OOV Guaranteed
Como o vocabulário base são caracteres, qualquer string pode ser representada (no pior caso, como caracteres individuais):
"supercalifragilisticexpialidocious"
→ ["super", "cal", "if", "rag", "il", "istic", "exp", "ial", "id", "oc", "ious"]
# Ou no pior caso: ['s', 'u', 'p', 'e', 'r', ...]- Eficiência Multilíngue
Subwords funcionam naturalmente para múltiplos idiomas:
# Inglês
"running" -> ["run", "ning"]
# Alemão (palavra composta)
"Zusammenarbeit" -> ["Zu", "sammen", "arbeit"]
# zusammen = junto, arbeit = trabalho
# Japonês (mistura de scripts)
"東京タワー" -> ["東京", "タ", "ワー"]Variantes Modernas: WordPiece e SentencePiece
WordPiece (BERT, DistilBERT): (Schuster e Nakajima 2012; Wu et al. 2016)
Similar a BPE, mas usa likelihood maximization em vez de frequência bruta. A ideia é mergir pares que aumentam a probabilidade (likelihood) do corpus ser gerado pelo vocabulário:
Score(pair) = P(pair) / (P(left) × P(right))Ou equivalentemente em log-space (para estabilidade numérica):
Score(pair) = log P(pair) - (log P(left) + log P(right))Intuição: Este score mede quanto mais provável é ver os dois tokens juntos vs. separados. Se “un” e “happy” aparecem juntos muito mais frequentemente do que esperaríamos pela frequência individual de cada um, o score é alto e vale mergir em “unhappy”.
Exemplo:
- “un” aparece 1000× no corpus (P(un) = 0.001)
- “happy” aparece 500× no corpus (P(happy) = 0.0005)
- “unhappy” aparece 300× no corpus (P(unhappy) = 0.0003)
Se fossem independentes, esperaríamos “un” + “happy” juntos apenas 0.001 × 0.0005 = 0.0000005 vezes. Mas vemos 0.0003! Isso indica forte associação → alto score → merge.
Diferença vs. BPE: BPE mergeria simplesmente o par mais frequente (pode ser “e” + ” ” que aparece milhões de vezes mas é semanticamente vazio). WordPiece prefere pares que têm associação estatística forte, não apenas frequência alta.
Comparação Detalhada: BPE vs WordPiece
Na prática, a diferença de performance entre BPE e WordPiece é pequena, mas há nuances importantes que valem a pena entender.
Alguns estudos mostram diferenças sutis:
- Em WMT translation tasks, WordPiece e BPE alcançam BLEU scores quase idênticos (diferença < 0.5 BLEU)
- Em Penn Treebank language modeling, perplexity difere em ~1-3%
- Em downstream tasks (classificação, NER), diferença é tipicamente < 1% accuracy
O custo computacional, porém, difere significativamente:
- BPE: Mais rápido (~2-3× mais rápido que WordPiece)
- Simples contagem de pares e merge
- Pode processar 100M tokens em ~30 minutos em CPU single-core
- WordPiece: Mais custoso
- Precisa calcular probabilidades e scores para cada par
- Requer múltiplas passadas sobre o corpus
- Pode levar 2-3× mais tempo que BPE no mesmo hardware
Quando Escolher Cada Um:
| Critério | BPE | WordPiece |
|---|---|---|
| Velocidade de treinamento | Mais rápido | Mais lento |
| Simplicidade | Algoritmo simples | Mais complexo |
| Qualidade de segmentação | Boa | Ligeiramente melhor |
| Uso em produção | GPT, LLaMA, Mistral | BERT, DistilBERT |
| Suporte multilíngue | Excelente | Excelente |
Recomendação prática: Para novos projetos, podemos usar BPE (mais especificamente, SentencePiece com BPE (Kudo e Richardson 2018)) pela simplicidade e velocidade, a menos que seja necessário replicar exatamente um modelo BERT-like. A diferença de qualidade é negligível na maioria dos casos.
SentencePiece (T5, XLNet, LLaMA): (Kudo e Richardson 2018)
Trata input como sequência de bytes UTF-8 em vez de caracteres Unicode. Vantagens:
- Language-agnostic: Não precisa de regras de segmentação específicas por idioma
- Espaços são tokens:
é tratado como token especial▁(underscore) - Reversibilidade perfeita:
decode(encode(text)) == textsempre
Exemplo:
# SentencePiece
"Hello world" -> ["▁Hello", "▁world"]
# ▁ indica início de palavra
# Reversível:
["▁Hello", "▁world"] -> "Hello world"Isso permite processar qualquer idioma (incluindo idiomas sem espaços como Chinês/Japonês) uniformemente.
Como Treinar Seu Próprio Tokenizer
Até agora exploramos como tokenizers funcionam. Mas como você realmente treina um tokenizer customizado para seu domínio? A implementação prática é essencial para consolidar a compreensão dos conceitos apresentados.
Quando Treinar um Tokenizer Customizado:
Não treine um tokenizer do zero a menos que você tenha uma boa razão para isso. Tokenizers pré-treinados (GPT-4, LLaMA, etc.) funcionam muito bem para a maioria dos casos.
Podemos considerar um tokenizer customizado quando:
- Seu domínio tem vocabulário muito específico (médico, legal, código específico)
- Idiomas sub-representados em tokenizers existentes (línguas indígenas, dialetos)
- Você precisa otimizar eficiência de tokenização para seu corpus específico
- Vocabulário do tokenizer existente é muito grande/pequeno para suas necessidades
Não treinar quando:
- Seu domínio é bem coberto por tokenizers existentes (GPT-4, LLaMA)
- Você não tem dados suficientes (< 1M exemplos)
- O custo de re-treinar embeddings supera o benefício
Quantidade de Dados Necessária:
Para treinar um tokenizer de qualidade:
- Mínimo: 10M tokens (~5MB de texto)
- Suficiente para vocabulário básico, mas cobertura limitada
- Recomendado: 100M-1B tokens (50MB-500MB)
- Boa cobertura de palavras comuns e raras
- Usado por modelos de pesquisa e domínios específicos
- Ideal: 10B+ tokens (5GB+)
- Cobertura excelente, incluindo termos raros
- Usado por modelos de produção (GPT, LLaMA)
Regra prática: Mais dados = melhor cobertura vocabular, mas retornos diminuem após ~1B tokens para a maioria dos domínios.
Escolha de Vocab Size:
Trade-off fundamental entre eficiência e granularidade:
| Vocab Size | Uso Típico | Pros | Cons |
|---|---|---|---|
| 8K-16K | Modelos pequenos, idiomas específicos | Rápido, poucos parâmetros | Tokens longos, menos eficiente |
| 32K-50K | Modelos médios (GPT-2, BERT) | Bom balanço | Padrão clássico |
| 50K-100K | Modelos grandes modernos | Eficiência melhorada | Mais parâmetros |
| 128K+ | Modelos state-of-the-art (GPT-4, LLaMA 3) | Máxima eficiência, multilíngue | Embeddings grandes |
Treinamento Prático com HuggingFace Tokenizers: (HuggingFace 2024; Wolf et al. 2020)
from tokenizers import (
Tokenizer,
models,
pre_tokenizers,
trainers,
processors
)
# 1. Configurar o modelo (BPE)
tokenizer = Tokenizer(models.BPE())
# 2. Pre-tokenização (como dividir texto antes de BPE)
tokenizer.pre_tokenizer = pre_tokenizers.ByteLevel(add_prefix_space=False)
# 3. Configurar trainer
trainer = trainers.BpeTrainer(
vocab_size=50000, # Tamanho do vocabulário
min_frequency=2, # Ignorar tokens que aparecem < 2 vezes
special_tokens=[ # Tokens especiais
"<s>", # Start of sequence
"</s>", # End of sequence
"<unk>", # Unknown token
"<pad>", # Padding
],
show_progress=True
)
# 4. Treinar em arquivos
files = ["data/train.txt", "data/validation.txt"]
tokenizer.train(files, trainer)
# 5. Post-processamento (adicionar tokens especiais)
tokenizer.post_processor = processors.ByteLevel(trim_offsets=False)
# 6. Salvar
tokenizer.save("my_tokenizer.json")
# Tempo esperado:
# - 100M tokens: ~5-10 minutos em CPU moderna
# - 1B tokens: ~30-60 minutos
# - 10B tokens: ~3-6 horasRegras de Pre-Tokenization:
Pre-tokenização define como dividir texto antes de aplicar BPE.
1. Whitespace Handling
# Opção 1: Whitespace simples
pre_tokenizers.Whitespace()
# Opção 2: ByteLevel (preserva espaços como ▁)
pre_tokenizers.ByteLevel(add_prefix_space=True)
# Opção 3: Metaspace (usado por SentencePiece)
pre_tokenizers.Metaspace()2. Pontuação
# Separar pontuação (útil para código)
pre_tokenizers.Punctuation(behavior="isolated")
# Ou manter com palavras (melhor para prosa)
pre_tokenizers.Punctuation(behavior="contiguous")3. Números
# Tratar dígitos individualmente (melhor para math reasoning)
pre_tokenizers.Digits(individual_digits=True)
# Ou manter números juntos
pre_tokenizers.Digits(individual_digits=False)4. Composição (Sequence)
# Combinar múltiplas pre-tokenization rules
from tokenizers import pre_tokenizers
tokenizer.pre_tokenizer = pre_tokenizers.Sequence([
pre_tokenizers.Whitespace(),
pre_tokenizers.Punctuation(behavior="isolated"),
pre_tokenizers.Digits(individual_digits=True)
])Validação do Tokenizer Treinado:
Após treinar, valide a qualidade:
# 1. Testar tokenização em exemplos
test_texts = [
"The quick brown fox jumps over the lazy dog.",
"Código Python: def fibonacci(n): return n",
"Número: 123456789"
]
for text in test_texts:
tokens = tokenizer.encode(text).tokens
print(f"Text: {text}")
print(f"Tokens ({len(tokens)}): {tokens}\n")
# 2. Calcular fertility rate (tokens por palavra)
#
# FERTILITY RATE: Métrica crucial para avaliar eficiência de tokenização
# Mede quantos tokens são necessários, em média, para representar uma palavra
#
# Fórmula: Fertility = Total de Tokens / Total de Palavras
#
# Interpretação:
# - Fertility ≈ 1.0: IDEAL! Em média, 1 palavra = 1 token
# Exemplo: "hello world" → ["hello", "world"] = 2 tokens / 2 palavras = 1.0
#
# - Fertility ≈ 1.2-1.5: BOM! Tokenização eficiente
# Exemplo: "unhappiness" → ["un", "happiness"] = 2 tokens / 1 palavra = 2.0 para esta palavra
# Mas médio sobre corpus inteiro é ~1.2-1.5 (palavras simples compensam as compostas)
#
# - Fertility > 2.0: RUIM! Vocabulário muito pequeno
# Palavras sendo fragmentadas excessivamente → sequências muito longas → mais custo
#
# - Fertility < 1.0: IMPOSSÍVEL! Cada palavra precisa de pelo menos 1 token
#
# Por que isso importa?
# - Fertility alto → mais tokens → mais computação → maior custo de API
# - Fertility alto → sequências mais longas → pode exceder context window
# - Fertility baixo → tokenização eficiente → melhor performance → menor custo
def fertility_rate(texts):
total_words = sum(len(text.split()) for text in texts)
total_tokens = sum(len(tokenizer.encode(text).tokens) for text in texts)
return total_tokens / total_words
fertility = fertility_rate(validation_texts)
print(f"Fertility rate: {fertility:.2f}")
# Interpretação do resultado
if fertility < 1.2:
print("✅ EXCELENTE: Tokenização muito eficiente!")
elif fertility < 1.5:
print("✅ BOM: Tokenização eficiente")
elif fertility < 2.0:
print("⚠️ MODERADO: Tokenização aceitável mas pode melhorar")
else:
print("❌ RUIM: Vocabulário muito pequeno, considere aumentar vocab_size")
# 3. Verificar cobertura de vocabulário
vocab = tokenizer.get_vocab()
print(f"Vocab size: {len(vocab)}")
print(f"Most common tokens: {sorted(vocab.items(), key=lambda x: x[1])[:20]}")
# 4. Checar tokens <unk> em validação
unk_id = vocab["<unk>"]
unk_count = sum(1 for text in validation_texts
for token_id in tokenizer.encode(text).ids
if token_id == unk_id)
print(f"<unk> rate: {unk_count / total_tokens:.4%}")
# Ideal: < 0.1% (quase nenhum unknown)Armadilhas Comuns:
- Vocab muito pequeno: Fertility rate alta (>2.0), muitos tokens por palavra
- Vocab muito grande: Muitos tokens raros (frequência < 10), embeddings subtreinadas
- Pre-tokenization errada: Palavras quebradas incorretamente, números fragmentados
- Dados insuficientes: Alto
<unk>rate em validação, cobertura pobre - Não incluir special tokens: Problemas ao treinar modelo depois
Integração com Modelos:
Após treinar tokenizer, você precisa treinar embeddings correspondentes:
from transformers import GPT2Config, GPT2LMHeadModel
# Carregar tokenizer customizado
from transformers import PreTrainedTokenizerFast
tokenizer = PreTrainedTokenizerFast(tokenizer_file="my_tokenizer.json")
# Criar modelo com vocab size correto
config = GPT2Config(vocab_size=len(tokenizer))
model = GPT2LMHeadModel(config)
# Agora treinar modelo do zero com esse tokenizer
# (ou fazer vocabulary extension se partir de modelo existente)Resumo de Decisões:
| Aspecto | Recomendação | Justificativa |
|---|---|---|
| Algoritmo | BPE via SentencePiece | Simples, rápido, bem suportado |
| Vocab Size | 32K-50K (padrão), 128K (avançado) | Balanço eficiência/cobertura |
| Dados | Mínimo 100M tokens | Cobertura vocabular adequada |
| Pre-tokenization | ByteLevel ou Metaspace | Preserva informação de espaços |
| Special tokens | Sempre incluir <s>, </s>, <unk>, <pad> |
Necessário para treinamento |
| Tempo | Espere 30min-2h para 1B tokens | Planeje adequadamente |
Representações Contextualizadas: O que Está Dentro dos Vetores
Um dos avanços dos Transformers em relação a word embeddings estáticos (como word2vec e GloVe) é que eles produzem representações contextualizadas. Embeddings estáticos atribuem um único vetor fixo para cada palavra, independente do contexto, “bank” sempre tem a mesma representação, seja “bank of the river” (margem) ou “bank is closed” (banco financeiro).
Transformers resolvem isso computando representações dinamicamente para cada ocorrência:
# Word2Vec (estático)
"The bank of the river" -> bank = [0.2, -0.5, 0.8, ...] # sempre igual
"The bank is closed" -> bank = [0.2, -0.5, 0.8, ...] # sempre igual
# Transformer (contextualizado)
"The bank of the river" -> bank₁ = [0.1, -0.3, 0.9, ...] # "margem"
"The bank is closed" -> bank₂ = [0.8, 0.5, -0.2, ...] # "banco financeiro"A distância vetorial entre bank₁ e bank₂ pode ser maior que a distância entre bank₁ e river, refletindo que “bank (margem)” está semanticamente mais próximo de “river” que de “bank (banco)”.
Estas representações contextualizadas capturam múltiplos níveis de informação linguística simultaneamente:
- Informação Sintática: Parte do discurso (substantivo, verbo), estrutura gramatical, relações de dependência
- Informação Semântica: Significado da palavra, relações semânticas (sinonímia, antonímia, hiperonímia)
- Informação Contextual: Significado específico derivado do contexto imediato (desambiguação)
- Conhecimento Factual: Propriedades e fatos sobre entidades (“Paris é capital da França”)
Pesquisas em interpretabilidade revelaram que diferentes camadas de um Transformer se especializam em diferentes tipos de informação (Rogers, Kovaleva, e Rumshisky 2020; Tenney, Das, e Pavlick 2019), formando uma hierarquia de representações. Isso pode ser visualizado da seguinte forma:
Camadas Iniciais (1-4): Informação sintática e superficial
- Part-of-speech tagging (~95% accuracy na camada 2)
- Segmentação de constituintes sintáticos
- Detecção de pontuação e capitalização
Camadas Intermediárias (5-8): Informação semântica e factual
- Desambiguação de sentido de palavras (word sense disambiguation)
- Relações semânticas entre palavras
- Conhecimento factual básico (entidades, relações)
Camadas Finais (9-12+): Informação task-specific e abstrata
- Representações otimizadas para a tarefa de predição
- Raciocínio mais complexo e inferências
- Composição semântica de alta ordem
Esta estrutura hierárquica é análoga a como CNNs (redes neurais convolucionais) aprendem features visuais:
- Camadas iniciais: Detectam edges, texturas básicas
- Camadas intermediárias: Detectam partes de objetos (olhos, rodas)
- Camadas finais: Detectam objetos completos e cenas complexas
Isso tem uma implicação prática: se você está fazendo fine-tuning, muitas vezes vale congelar as camadas iniciais (que aprendem linguagem geral) e treinar apenas as finais (task-specific). Isso reduz drasticamente o custo computacional e dados necessários. Veremos isso em detalhes no próximo capítulo.
Capacidades Emergentes: Além do Treinamento
Um dos fenômenos mais surpreendentes dos LLMs é a emergência de capacidades que não foram explicitamente treinadas (Wei, Tay, et al. 2022). Modelos suficientemente grandes demonstram comportamentos qualitativamente novos que modelos menores simplesmente não exibem, mesmo treinados nos mesmos dados.
Isso não é apenas “fazer a mesma coisa melhor”, é desenvolver capacidades novas. Considere a analogia com transições de fase na física: água a 99°C e 101°C não é apenas “mais quente ou mais fria”, é qualitativamente diferente (líquido vs. vapor). Similarmente, um modelo de 1B parâmetros e um de 100B não diferem apenas em “qualidade”, mas em quais tarefas conseguem realizar.
Entre as capacidades emergentes mais documentadas destacam-se: In-Context Learning (aprender de exemplos no prompt), Chain-of-Thought Reasoning (raciocínio passo-a-passo), e Instruction Following (seguir instruções complexas). Estas capacidades são fundamentais para construir agentes de IA eficazes.
In-Context Learning: Aprendizado Sem Atualizar Pesos
In-Context Learning (ICL) é a capacidade do modelo aprender novas tarefas a partir de poucos exemplos fornecidos no próprio prompt, sem atualizar pesos do modelo (Brown et al. 2020). Imagine que você mostra 3 exemplos de tradução inglês→francês no prompt, e o modelo “aprende” o padrão e traduz corretamente uma quarta frase—mesmo que nunca tenha sido explicitamente treinado para “seguir exemplos no contexto”.
Exemplo conceitual:
Input: [Exemplo 1] [Exemplo 2] [Exemplo 3] [Nova Tarefa]
Output: Modelo generaliza o padrão e resolve a nova tarefaPor que ICL é surpreendente?
Durante o treinamento, o modelo só viu a tarefa de “prever o próximo token”. Nunca foi treinado explicitamente para:
- Detectar padrões em sequências de exemplos
- Generalizar de poucos exemplos (few-shot learning)
- Aplicar padrões aprendidos no contexto a novos casos
No entanto, essa capacidade de meta-aprendizado emerge em modelos grandes (~10B+ parâmetros). Modelos menores não exibem ICL de forma consistente.
Variantes de ICL
ICL se manifesta em três formas principais:
- Zero-shot: Apenas instrução, sem exemplos (“Traduza para francês: Hello”)
- Few-shot: Poucos exemplos (1-10) antes da tarefa real
- Many-shot: Muitos exemplos (10-100+) explorando o context window completo
No Capítulo 4, você aprenderá como usar cada variante efetivamente, incluindo estratégias de seleção e ordenação de exemplos.
Chain-of-Thought: Raciocínio Explícito Passo-a-Passo
Chain-of-Thought (CoT) é a capacidade de resolver problemas complexos através de raciocínio passo-a-passo explícito (Wei, Wang, et al. 2022). Em vez de gerar a resposta final diretamente, o modelo “mostra o trabalho”—decompondo o problema em etapas intermediárias verificáveis.
LLMs são treinados para prever o próximo token. Para problemas simples que podem ser “memorizados” isso funciona ("2 + 2 =" → "4"). Mas para problemas que requerem múltiplos passos de raciocínio, gerar a resposta diretamente frequentemente falha.
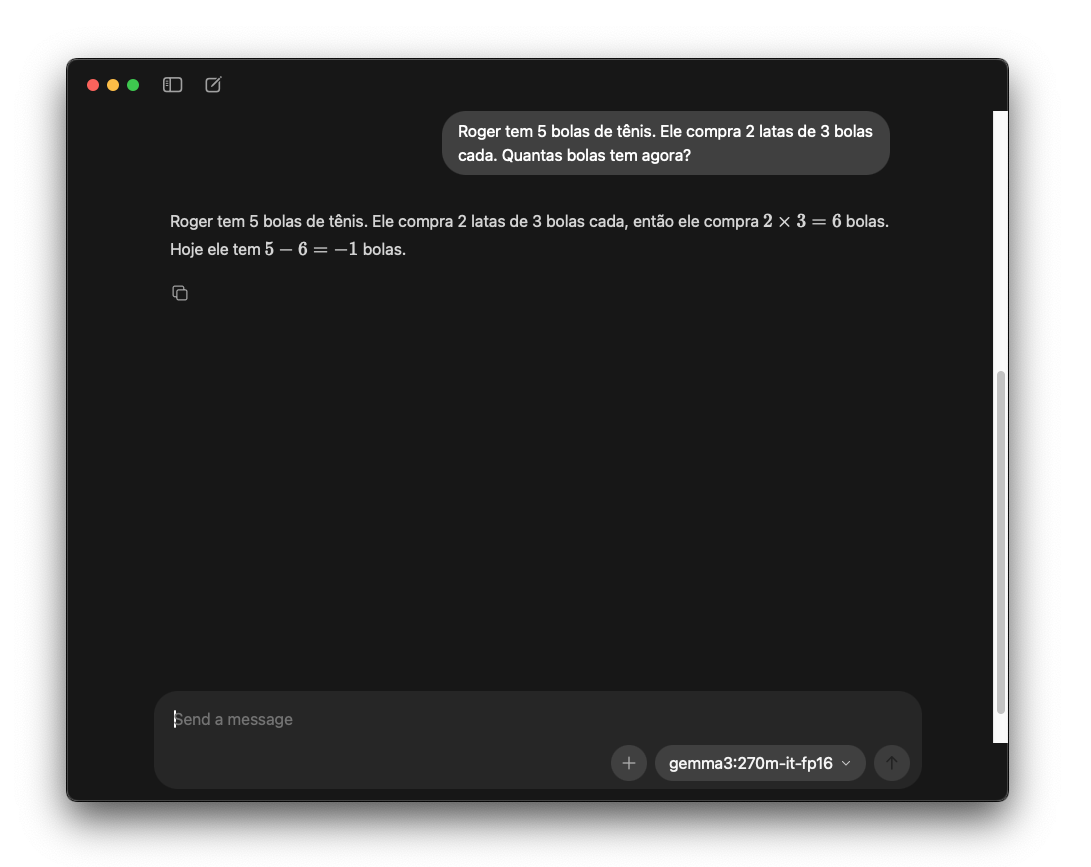
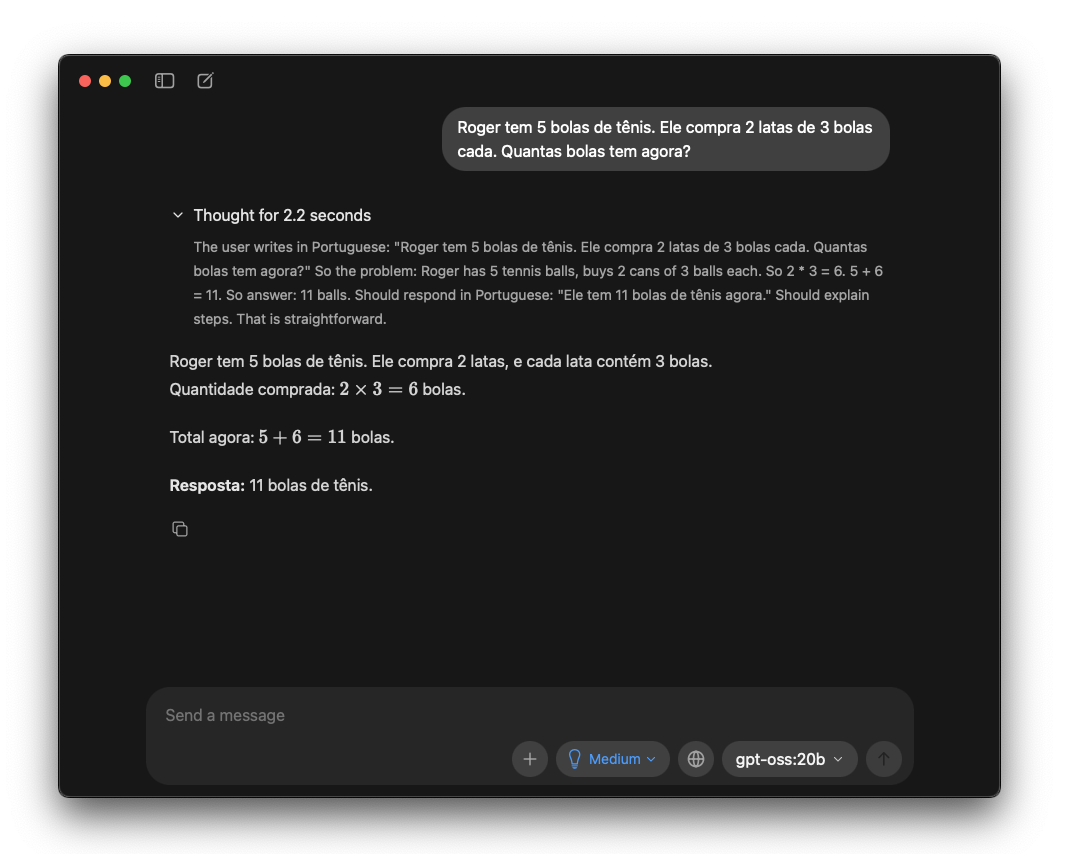
Exemplo: “Roger tem 5 bolas. Ele compra 2 latas de 3 bolas cada. Quantas bolas tem agora?”
- Modelo pequeno (~1B): “8” (errado—tentou “adivinhar” sem raciocinar)
- Modelo grande (~70B) com CoT: Gera raciocínio passo-a-passo correto até chegar em “11”
Veja as imagens abaixo comparando um modelo pequeno (gemma3:270m-it-fp16) que falha vs. um modelo grande (gpt-oss:20b) que raciocina corretamente:
Existem duas hipóteses principais que explicam o sucesso de CoT:
- Espaço de Trabalho Intermediário: Gerando tokens intermediários, o modelo cria “espaço para pensar” em vez de comprimir todo o raciocínio em uma única predição
- Padrão de Treinamento: Dados de treinamento incluem tutoriais, explicações matemáticas, provas—exemplos de raciocínio passo-a-passo. CoT ativa esse padrão aprendido
Wei, Wang, et al. (2022) descobriram que simplesmente adicionar “Let’s think step by step” ao prompt melhora significativamente a acurácia em tarefas de raciocínio:
- GSM8K (problemas matemáticos): +35% de acurácia (17% → 52% em PaLM 540B)
- SVAMP (word problems aritméticos): +28% de acurácia (64% → 92%)
- AQuA (álgebra): +40% de acurácia
No nosso contexto, na construção de agentes, CoT acaba sendo essencial para permitir que o modelo raciocine sobre planos de ação complexos.
- Permite decomposição de tarefas complexas em etapas gerenciáveis
- Torna o raciocínio inspecionável e debugável (essencial em produção)
- Habilita validação de etapas intermediárias antes de continuar
- Possibilita auditoria através de logs de raciocínio
No Capítulo 4, você dominará técnicas práticas de CoT: zero-shot vs. few-shot CoT, self-consistency, e quando aplicar cada variante.
Instruction Following: Execução de Instruções Complexas
Instruction Following é a capacidade de interpretar e executar instruções complexas em linguagem natural, incluindo:
- Instruções multi-etapa (“Primeiro faça X, depois Y, então Z”)
- Condicionais (“Se houver erro, reporte; caso contrário, aprove”)
- Restrições de formato (“Responda em JSON”, “Use no máximo 3 frases”)
Isso é surpreendente porque o modelo foi treinado apenas em next-token prediction—nunca foi explicitamente ensinado a:
- Decompor instruções complexas em sub-tarefas
- Executar condicionais (“se X então Y, senão Z”)
- Manter contexto e estado entre etapas
- Formatar saída conforme especificações arbitrárias
No entanto, modelos grandes (~70B+) conseguem seguir instruções extremamente complexas com alta fidelidade. Esta capacidade “emerge” quando os modelos atingem escala suficiente.
Implicação prática para engenheiros
Modelos maiores não são apenas “modelos que fazem as mesmas coisas melhor”—eles têm capacidades qualitativamente diferentes. Um modelo de 1B parâmetros pode não conseguir fazer certas tarefas que um modelo de 70B faz facilmente, independentemente de quanto você o fine-tune.
Por que Capacidades Emergem?
A ciência exata da emergência ainda não é completamente compreendida, mas temos hipóteses principais:
- Threshold de Complexidade: Certas tarefas requerem “circuitos” neurais de tamanho mínimo. Modelos abaixo desse threshold simplesmente não conseguem representar a lógica necessária
- Composição de Habilidades Simples: Capacidades complexas surgem da composição de padrões mais simples aprendidos durante o treinamento
- Generalização em Escala: Com mais parâmetros e dados, o modelo aprende padrões mais abstratos que generalizam para tarefas não vistas
Neste capítulo você compreendeu o que são capacidades emergentes e por que elas surgem durante o treinamento. No Capítulo 4 (Fundamentos de Prompting e Raciocínio), você dominará como usar essas capacidades na prática através de técnicas avançadas de prompt engineering.
Pratique o que Aprendeu
Este capítulo apresentou conceitos fundamentais sobre treinamento de foundation models, incluindo pré-treinamento, curadoria de dados, tokenização e capacidades emergentes.
Para consolidar seu entendimento através de implementação prática, consulte os Exercícios Práticos do Capítulo 2, que incluem:
- Análise de Eficiência de Tokenização: Compare tokenização entre idiomas e calcule custos de API
- Data Cleaning Pipeline: Implemente pipeline completo de limpeza de dados
- Treinamento de Tokenizer BPE: Treine seu próprio tokenizer do zero
Os exercícios fornecem código executável e guias passo a passo para aplicação prática dos conceitos apresentados.
Conclusão
Neste capítulo, exploramos os fundamentos de como foundation models são treinados, focando em quatro pilares essenciais que determinam suas capacidades:
1. Self-Supervised Learning e Métricas de Treinamento
Compreendemos como modelos aprendem através do paradigma de predição do próximo token, uma tarefa aparentemente simples que, em escala massiva, produz representações ricas de linguagem. Exploramos como medimos esse aprendizado através de loss function e perplexidade, e—criticamente—entendemos as limitações dessas métricas: perplexidade baixa não garante utilidade prática, e otimizar apenas para loss pode levar a modelos que “decoram” sem realmente compreender.
2. Dados de Pré-Treinamento: A Matéria-Prima do Conhecimento
Investigamos a composição de datasets modernos (Common Crawl, livros, código, Wikipedia) e o processo meticuloso de data cleaning que transforma petabytes de texto bruto em dados de alta qualidade. Vimos que data cleaning não é apenas um passo técnico—envolve decisões éticas complexas sobre o que incluir ou excluir, com impactos profundos nas capacidades e vieses do modelo resultante. A qualidade e diversidade dos dados de treinamento são fundamentais: “garbage in, garbage out” nunca foi tão verdadeiro quanto em foundation models.
3. Tokenização: A Camada Crítica Entre Texto e Modelo
Mergulhamos profundamente em como texto é convertido em sequências numéricas que modelos podem processar. Exploramos diferentes estratégias (tokenização por caracteres, palavras, e subword tokenization via BPE e variantes) e suas implicações práticas. Vimos como escolhas de tokenização afetam não apenas eficiência computacional, mas capacidades fundamentais do modelo: aritmética, processamento multilíngue, compreensão de código, e até mesmo custos de API. Aprendemos a treinar tokenizers customizados e avaliar sua qualidade através de métricas como fertility rate.
4. Capacidades Emergentes: O Fenômeno Surpreendente
Descobrimos que modelos suficientemente grandes desenvolvem capacidades que nunca foram explicitamente treinadas—um fenômeno chamado emergência. Exploramos três capacidades emergentes fundamentais: In-Context Learning (aprender de exemplos no prompt sem atualizar pesos), Chain-of-Thought Reasoning (raciocínio passo-a-passo explícito), e Instruction Following (executar instruções complexas). Compreendemos por que essas capacidades emergem (thresholds de escala, composição de padrões aprendidos) e suas implicações para construção de agentes. No Capítulo 4, você aprenderá como usar essas capacidades na prática através de técnicas de prompt engineering.
Aplicação Prática: Por que isso importa para Agentes de IA
Este conhecimento não é puramente acadêmico—ele é essencial para construir agentes de IA eficazes:
Seleção de Modelos: Entender como modelos foram treinados ajuda a escolher o modelo certo para cada tarefa. Um modelo treinado predominantemente em código (Code Llama) terá capacidades diferentes de um treinado em linguagem natural geral.
Otimização de Prompts: Conhecer limitações de tokenização permite escrever prompts mais eficientes, reduzindo custos e latência.
Debugging de Comportamento: Quando um agente falha em uma tarefa, entender o processo de treinamento ajuda a diagnosticar se é uma limitação fundamental do modelo ou um problema de prompt/configuração.
Gerenciamento de Custos: Compreender que custos de API são baseados em tokens—e que tokenização varia entre idiomas—permite estimativas precisas de custo operacional.
Preparação para o Próximo Capítulo
Com essa fundação sólida sobre como modelos são treinados, estamos prontos para explorar como adaptá-los para casos de uso específicos. No próximo capítulo, mergulharemos em fine-tuning e técnicas de otimização: como pegar um modelo pré-treinado e especializá-lo para suas tarefas específicas, balanceando qualidade, custo e latência para construir agentes de IA eficientes em produção.
Exemplos de Código Completos
Esta seção contém implementações completas dos conceitos apresentados neste capítulo.
Exemplo 1: Métricas de Qualidade de Dados
Implementação completa das heurísticas para avaliar qualidade de texto em dados de treinamento.
import math
from collections import Counter
def calculate_entropy(text):
"""
Calcula entropia de Shannon dos tokens (diversidade vocabular).
Entropia mede a "surpresa média" ou diversidade do vocabulário.
- Baixa entropia: Texto repetitivo (ruim)
- Alta entropia: Vocabulário diverso (bom)
"""
words = text.lower().split()
if not words:
return 0.0
# Conta frequência de cada palavra
word_counts = Counter(words)
total_words = len(words)
# Calcula entropia: H = -Σ(p(x) * log2(p(x)))
entropy = 0.0
for count in word_counts.values():
probability = count / total_words
entropy -= probability * math.log2(probability)
return entropy
def count_stopwords(text):
"""
Conta stopwords comuns (palavras funcionais).
Stopwords são palavras gramaticais comuns como "the", "is", "a".
Proporção adequada de stopwords indica linguagem natural.
"""
# Stopwords básicas em inglês
stopwords = {
'the', 'be', 'to', 'of', 'and', 'a', 'in', 'that', 'have', 'i',
'it', 'for', 'not', 'on', 'with', 'he', 'as', 'you', 'do', 'at',
'this', 'but', 'his', 'by', 'from', 'they', 'we', 'say', 'her', 'she',
'or', 'an', 'will', 'my', 'one', 'all', 'would', 'there', 'their'
}
words = text.lower().split()
stopword_count = sum(1 for word in words if word in stopwords)
return stopword_count
def count_uppercase(text):
"""Conta caracteres maiúsculos (detecta spam/shouting)."""
return sum(1 for c in text if c.isupper())
def count_duplicates(lines):
"""
Calcula proporção de linhas duplicadas.
Alto índice de duplicação pode indicar:
- Conteúdo auto-gerado
- Logs repetitivos
- Spam
"""
if not lines:
return 0.0
line_counts = Counter(lines)
duplicates = sum(count - 1 for count in line_counts.values() if count > 1)
return duplicates / len(lines)
def is_high_quality(text):
"""
Aplica múltiplas heurísticas para filtrar texto de baixa qualidade.
Returns:
True se o texto passa em todos os filtros
"""
words = text.split()
if len(words) == 0:
return False
# Heurística 1: Proporção de stopwords
stopword_ratio = count_stopwords(text) / len(words)
if stopword_ratio < 0.2: # Muito técnico ou spam
return False
# Heurística 2: Entropia de tokens (diversidade vocabular)
token_entropy = calculate_entropy(text)
if token_entropy < 3.0: # Muito repetitivo
return False
# Heurística 3: Proporção de letras maiúsculas
if len(text) > 0:
upper_ratio = count_uppercase(text) / len(text)
if upper_ratio > 0.3: # MUITO SPAM ASSIM
return False
# Heurística 4: Linhas duplicadas
duplicate_lines = count_duplicates(text.split('\n'))
if duplicate_lines > 0.5: # Mais de 50% repetido
return False
return True
# Exemplo de uso
text_good = """
Natural language processing has revolutionized how we interact with machines.
Modern transformer models can understand context and generate human-like text.
These capabilities emerge from training on massive datasets.
"""
text_bad_spam = """
BUY NOW!!! CLICK HERE!!! LIMITED OFFER!!!
HURRY UP!!! DON'T MISS OUT!!!
"""
print(f"Texto bom: {is_high_quality(text_good)}") # True
print(f"Texto spam: {is_high_quality(text_bad_spam)}") # FalseExemplo 2: Deduplicação com MinHash e LSH
Implementação completa de deduplicação eficiente usando MinHash e Locality-Sensitive Hashing.
from datasketch import MinHash, MinHashLSH
def get_minhash(text, num_perm=128):
"""
Cria MinHash signature de um documento.
MinHash cria uma "impressão digital" compacta que preserva
similaridade de Jaccard entre documentos.
Args:
text: Documento de entrada
num_perm: Número de permutações (trade-off precisão vs memória)
Returns:
MinHash object representando o documento
"""
m = MinHash(num_perm=num_perm)
# Tokeniza em palavras (ou use n-gramas para mais robustez)
words = text.lower().split()
for word in words:
m.update(word.encode('utf8'))
return m
def deduplicate_documents(docs, threshold=0.8):
"""
Remove documentos duplicados ou near-duplicates.
Args:
docs: Dict {doc_id: text}
threshold: Similaridade Jaccard mínima para considerar duplicata
Returns:
Set de doc_ids duplicados (para remover)
"""
# Configuração LSH
# threshold=0.8 significa detectar docs com Jaccard similarity >= 80%
lsh = MinHashLSH(threshold=threshold, num_perm=128)
duplicates_to_remove = set()
doc_hashes = {}
# Indexar documentos
for doc_id, text in docs.items():
m = get_minhash(text)
doc_hashes[doc_id] = m
# Buscar duplicatas já indexadas
duplicates = lsh.query(m)
if duplicates:
# Se já existe duplicata, marcar este documento para remoção
duplicates_to_remove.add(doc_id)
print(f"Duplicata encontrada: {doc_id} similar a {duplicates}")
else:
# Se não é duplicata, adicionar ao índice
lsh.insert(doc_id, m)
return duplicates_to_remove
# Exemplo de uso
docs = {
"doc1": "A capital da França é Paris",
"doc2": "Paris é a capital da França", # Near-duplicate de doc1
"doc3": "Berlin é a capital da Alemanha",
"doc4": "A França tem Paris como capital", # Near-duplicate de doc1
"doc5": "Londres é a capital da Inglaterra"
}
duplicates = deduplicate_documents(docs, threshold=0.7)
print(f"\nDocumentos duplicados: {duplicates}")
print(f"Documentos únicos: {set(docs.keys()) - duplicates}")
# Análise de performance
print(f"\nRedução: {len(duplicates)}/{len(docs)} documentos removidos")
print(f"Taxa de compressão: {(1 - len(duplicates)/len(docs)) * 100:.1f}%")Por que MinHash + LSH é eficiente:
- MinHash: Reduz documento de milhares de palavras para ~128 números
- LSH: Busca em tempo O(1) médio em vez de O(n)
- Escalável: Funciona com bilhões de documentos
Parâmetros importantes:
num_perm: Mais permutações = mais precisão, mais memória (128 é padrão)threshold: Mais alto = apenas duplicatas muito similares (0.8-0.9 típico)num_bands: Trade-off sensibilidade vs false positives